开始
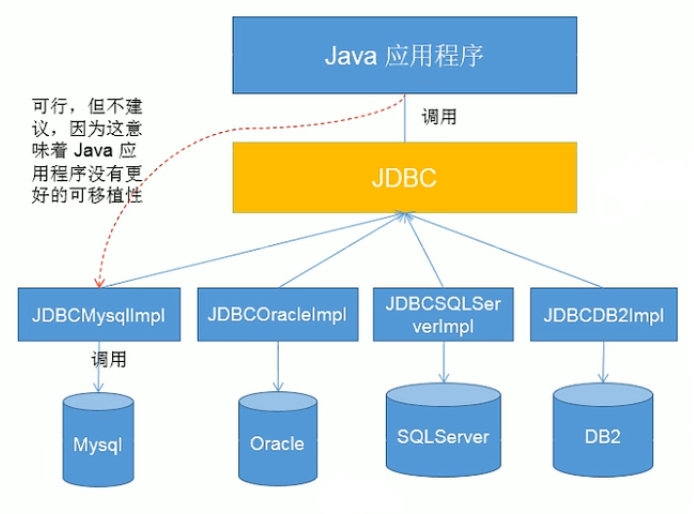
JDBC 是 java 操作数据库的一组 API
JDBC 只是 java 操作数据库的接口,具体的实现由数据库厂商实现各自的驱动
数据库连接
使用数据库首先要与数据库进行连接,JDBC 有多种方式可以连接到数据库
Driver
通过 java 的 Driver 抽象类连接,使用具体数据库驱动的 driver 对象实例化
传入 url,properties,调用 connect 返回连接对象
url 格式:jdbc:mysql://ip:3306/database_name
properties 对象调用 setProperties(),传入账号密码的键值对
反射连接
使用反射将连接过程封装
1 | Class<?> cl = Class.forName("com.mysql.cj.jdbc.Driver"); |
DriverManager
DriverManager 可以管理多个 Driver 对象,可以通过 DriverManager 获取连接
1 | DriverManager.registerDriver(driver); |
类加载
driver 对象在类加载时,会自动注册
1 | Class.forname("com.mysql.cj.jdbc.Driver"); // 加载类 |
操作数据库
jdbc 中有三个接口定义了数据库的调用
- Statement:执行静态的 SQL 语句,容易产生 SQL 注入问题
- PreparedStatement:将 SQL 语句预编译后存储在对象中,可用于多次高效地调用
- CallableStatement:用于执行 SQL 存储过程
ORM 思想
- 一张表对应一个 Java 类
- 一条记录对应一个 Java 对象
- 一个字段对应一个 Java 对象的属性
PreparedStatement
调 connection.preparedStatement(sql) 获取 preparedStatement 对象
传入的 sql 语句支持动态参数,使用?占位
调用 preparedStatement.setXXX(index, value) 设置动态参数,index 从 1 开始,再调用 execute() 执行
在 sql 语句中若表名为关键字,则使用`` 着重符将表名括起来
查询结果操作
调用 executeQuery() 返回一个 ResultSet 对象
处理结果集
resultSet.next():判断下一条是否有数据resultSet.getXXX(index):获取字段resultSet.getMetaData():返回结果集的元数据,可以获取列数、列名
对于一个任意字段数量的对象的查询
1 | public static Book queryBook(String sql, Object... args) { |
操作 BLOB 类型字段
BLOB 类型为二进制长文本数据
mysql 支持四种容量的 BLOB
- TinyBlob:255B
- Blob:65KB
- MediumBlob:16MB
- LongBlob:4GB
Blob 类型的参数需要传入一个 InputStream 对象,即需要存入的图片的输入流
读取 Blob 类型
1 | String type = metaData.getColumnTypeName(i + 1); |
批量插入
mysql 默认不支持批处理,需要在 URL 中传入参数开启批处理
1 | jdbc:mysql://localhost:3306/db?rewriteBatchedStatements=true |
批处理相当于构造多条语句并执行
操作流程
- 在构造完一条语句后 (设置完动态参数后),调用
preparedStatement.addBatch()将该语句存入一批中 - 调用
preparedStatement.executeBatch()执行当前批 - 调用
preparedStatement.clearBatch()清空当前批 - 在循环中可以控制批数
- 在数据库层面可以关闭自动提交,构成一层缓存,调用
connection.setAutoCommit(false) - 在语句全部执行完后,调用
connection.commit()提交到数据库
事务
基本概念
事务是数据库的一组操作,具有 ACID 属性
- 原子性:事务要么全部操作成功,要么全部失败
- 一致性:事务提交前后,数据库的状态必须保持一致
- 隔离性:多个事务并发时,事务操作之间互不干扰
- 持久性:一旦事务提交,事务造成的数据库变化是持久的
数据库自动提交
- DDL:对表结构的增删改,一定会提交
- DML:对记录的增删改,默认自动提交,可设置
autocommit = false取消自动提交 - 默认在关闭连接时自动提交
设置事务
- 取消自动提交,
connection.setAutoCommit(false); - 在捕获异常中调用
connection.rollback();回滚 - 在所有操作执行成功后调用
connection.commit();提交 - 在操作结束后,若连接没有关闭则应该重新设置自动提交
connection.setAutoCommit(true);
基本流程
1 | connection.setAutoCommit(false); |
数据库并发
设两个事务 T1,T2
- 脏读:T1 读取了 T2 已经更新但未提交的数据,此时 T2 回滚,T1 读取的数据无效 (脏数据)
- 不可重复读:T1 读取了一个字段,此时 T2 更新了该字段,T1 再读取该字段,前后读取数据不一致
- 幻读:T1 读取一个表,此时 T2 向该表插入了记录,T1 再读取该表,结果多了几条记录
隔离级别
- READ UNCOMMITTED:允许读取未被其他事物提交的变更,安全性最低
- READ COMMITTED:只允许事物读取其他事物已经提交的变更
- REPEATABLE READ:在事务执行期间,禁止其他事务对当前事务读取的字段进行更新
- SERIALIZABLE:类似同步,性能最低
相关 API
- 调用
connection.getTransactionIsolation()获取隔离级别 - 调用
connection.setTransactionIsolation()设置隔离级别
DAO
DAO 是 Data Access Object,数据库操作对象,里面封装了操作数据库的方法
DAO 操作规范
- 定义抽象父类 BaseDAO,实现一个通用的 DAO 对象
- 对于具体的表,定义相应的 DAO 接口,指明需要实现的方法
- 实现相应的 DAO 接口并继承 BaseDAO,将对象转换到 SQL 并调用 BaseDAO
中间的实现类 DAO 层将对象与 SQL 语句隔离开,调用方只考虑操作对象,BaseDAO 只考虑操作 SQL
数据库连接池
为所有数据库连接建立一个缓冲池,需要建立连接时,从连接池中取出连接使用,允许程序重复使用连接,降低建立连接开销
Druid 连接池
配置文件 jdbc.properties
1 | url=jdbc:mysql://localhost:3306/maxdb?rewriteBatchedStatements=true&useUnicode=true&characterEncoding=utf8 |
在 JDBCUtils 中创建连接池
1 | private static DataSource source; |
Apache-DBUtils
Apache 封装的数据库操作库
###QueryRunner
QueryRunner 中一共有 6 种方法
- execute(执行 SQL 语句)
- batch(批量处理语句)
- insert(执行 INSERT 语句)
- insertBatch(批量处理 INSERT 语句)
- query(SQL 中 SELECT 语句)
- update(SQL 中 INSERT,UPDATE 或 DELETE 语句)
ResultSetHandler
ResultSetHandler 是处理查询结果的处理器
- BeanHandler:将一条结果封装为对象,若查询结果有多条,则返回第一条记录的对象
- BeanListHandler:将多条结果封装为对象列表
- ArrayHandler:将一条结果的字段作为数组元素,一条结果作为一个数组返回
- ArrayListHandler:将多条结果封装为数组列表
- MapHandler:将一条结果的标签作为 key,字段值作为 value,返回一条结果的构成的 map
- MapListHandler:返回多条结果的 map 列表
- ScalerHandler:用于封装特殊值,如 count,max
关闭资源
1 | DBUtils.close(connection); |


