前言
在考研时学会了 KMP 算法的手算,没有深究它的算法实现(主要是也不咋考),今天在 LeetCode 上刷到 KMP 的题目,在此记录一下代码实现的理解
相关 LeetCode 题目
KMP 算法
KMP 算法主要就是两步
- 使用模式串生成 next 数组(本文使用的是 next[0]=-1 的版本)
- 使用 next 数组对匹配串进行匹配
以下称模式串为 P,匹配串为 S,P[i] 表示 P 的第 i 个字符,从 0 开始,S 同理
Talk is cheap. Show me the code. 直接上代码
1 | /** |
算法过程
以 LeetCode 第 28 题为例
生成 next 数组
首先说明函数中的定义
-
i:扫描 P 的主要指针,从 0 递增到字符串长度,不会减小
-
j:用于查找最长重合前后缀的指针,扫描时随 i 递增,查找前后缀时回退减小
-
next[l]=k:表示长度为 l 的子串 p[0, l - 1],它的最长重合前后缀的长度为 k
注意,在序列型的结构中,长度同时代表了索引,这一点在后面会用到
我们按照代码的执行一遍,使用的模式串 p="abac"
1 | void getNext(int* next, const string& p) { |
-
i = 0, j = -1, p[i] = aj == -1 判断为 true,令 next[++i]=++j,即 next[1] = 0
-
i = 1, j = 0, p[i] = b, p[j] = ap[i] == p[j] 判断为 false,令 j = next[j],即 j = -1
-
i = 1, j = -1, p[i] = bj == -1 判断为 true,next[2] = 0
-
i = 2, j = 0, p[i] = a, p[j] = ap[i] == p[j] 判断为 true,next[3] = 1
-
i = 3 退出循环,得到 next = {-1, 0, 0, 1}
Case1:p[i] = p[j]
我们首先研究 p[i] == p[j] 判断为 true,执行 next[i + 1] = j + 1 的情况
从上述过程中,首先可以看出只有在修改 next 数组时,i 才递增,则 next 的填入是随着 i 的递增进行的。执行 next[i + 1] = j + 1 表示将长度为 i + 1 的子串的最长重合前后缀长度设置为 j + 1,那么 p[i] 实际就是长度为 i + 1 的子串的最后一个字符(注意之前提到的长度同时代表了索引)
比如 next[2] 表示 [0, 1] 的长度为 2 的子串,而填入之前 i = 1,p[1] 就是该子串的最后一个字符
i 还有另一个意义,它指向子串后缀的最后一个字符,这应该很好理解,i 指向子串的最后一个字符,自然就是子串后缀的最后一个字符
现在弄清楚 p[i] 和 next[i + 1] 的关系之后,我们再来看看 p[j] 是什么
算法中始终是将 j + 1 的值赋给 next,而 next 的值表示子串的最长重合前后缀长度,则 j + 1 表示最长重合前后缀长度,同样地,赋值前的 j 表示的就是重合前后缀的最后一个字符下标,p[j] 就是重合前缀的最后一个字符
现在我们来画个一般情况的图,i 和 j 的指向如图所示
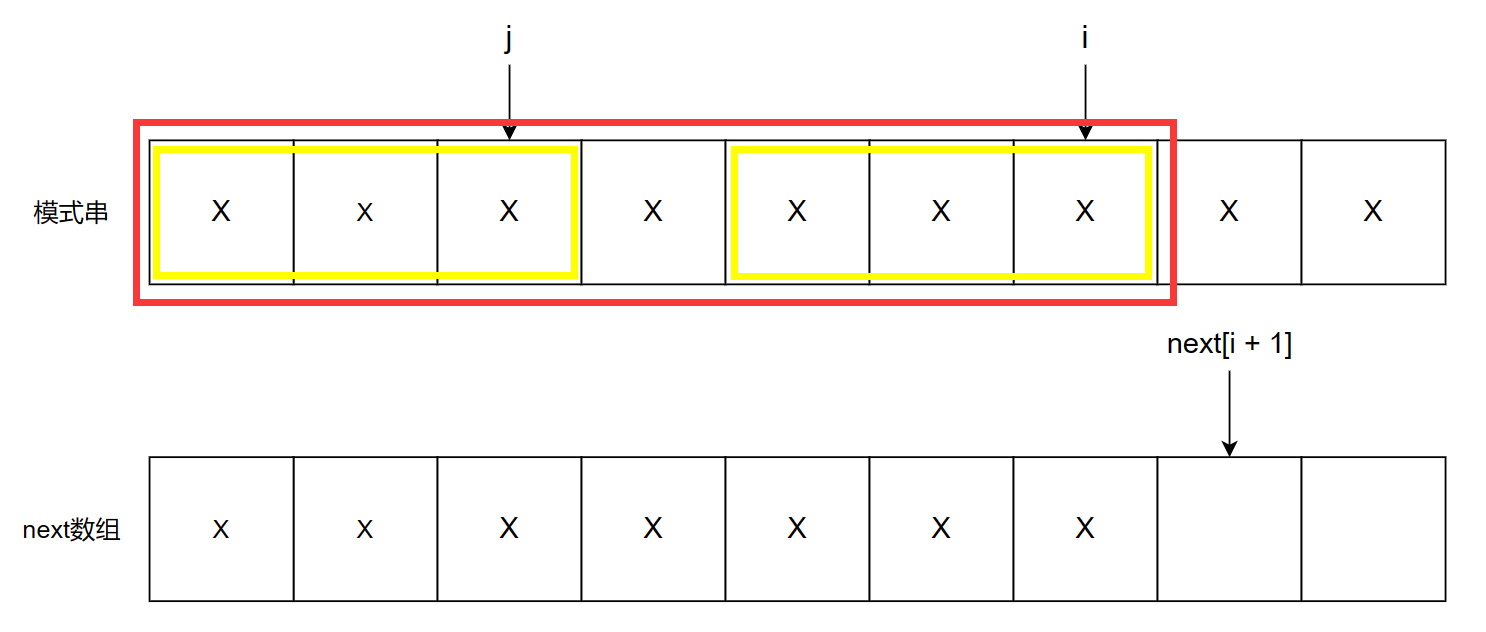
现在我们要填入 next[i + 1],那么考虑 p[0, i] 的子串,即图中红框标出的子串
假设next[i + 1] = j + 1 成功执行,那么就表示长度为 i + 1 的子串的最长重合前后缀长度为 j + 1,此时 j 指向重合前缀的最后一个字符,也就表示p[0, j] 为重合的前缀,那么重合的后缀就是 p[i - j, i],即图中黄框的部分
那么现在来看看为什么要比较 p[i] 和 p[j]
如上述,j 指向前缀的最后一个字符,i 指向后缀的最后一个字符,那么现在我们要填入 next[i + 1],就只需要比较前后缀的最后一个字符,就可以判定前后缀是否重合,为什么不需要比较前面的字符呢,这里包含了一个递归的思想,实际上前面的字符在填入 next[0] 到 next[i] 时已经比较过了
这种情况实际上是一种比较理想的情况,下面就这种情况举个例子
模式串 p="aaaa"
-
i = 0, j = -1, p[i] = aj == -1 判断为 true,
p[0, 0] = “a”,前缀为 p[0, -1],重合前后缀长度为 0,next[1] = 0 -
i = 1, j = 0, p[i] = a, p[j] = ap[i] == p[j] 判断为 true,
p[0, 1] = “aa”,前缀为 p[0, 0],重合前后缀长度为 1,next[2] = 1 -
i = 2, j = 1, p[i] = a, p[j] = ap[i] == p[j] 判断为 true,
p[0, 2] = “aaa”,前缀为 p[0, 1],重合前后缀长度为 2,next[3] = 2 -
i = 3 退出循环,得到 next = {-1, 0, 1, 2}
和上一个例子比较可以看出,相同长度的字符串,这种情况执行的循环次数会少一点,主要是少在没有执行 j = next[j] 这一步,下面我们看看这一步如何理解
Case2:p[i] != p[j]
要执行 j = next[j],实际上就是满足 j != -1 && p[i] != p[j]
当 p[i] != p[j] 时,说明当前比较的前缀和后缀的最后一个字符不相同,也就是当前比较的前后缀不重合,既然不重合,我们就需要查找一个位置使得前后缀重合,j = next[j] 就是那个查找的步骤
next[j] 的值是长度为 j 的子串的最长重合前后缀长度。这里需要理解两个信息,一个是长度为 j 的子串,当我们调用 next[j] 时,我们的视角就应该放到 p[0, j - 1] 的子串上了,也就是之前比较的前缀(不包含最后一个字符)。另一个是 j = next[j],这一句实际上就是定位到 p[0, j - 1] 这个子串中的重合前后缀的最后一个字符的下一个字符(模糊点理解就是定位到前缀的前缀,j 回退一步),如下图所示
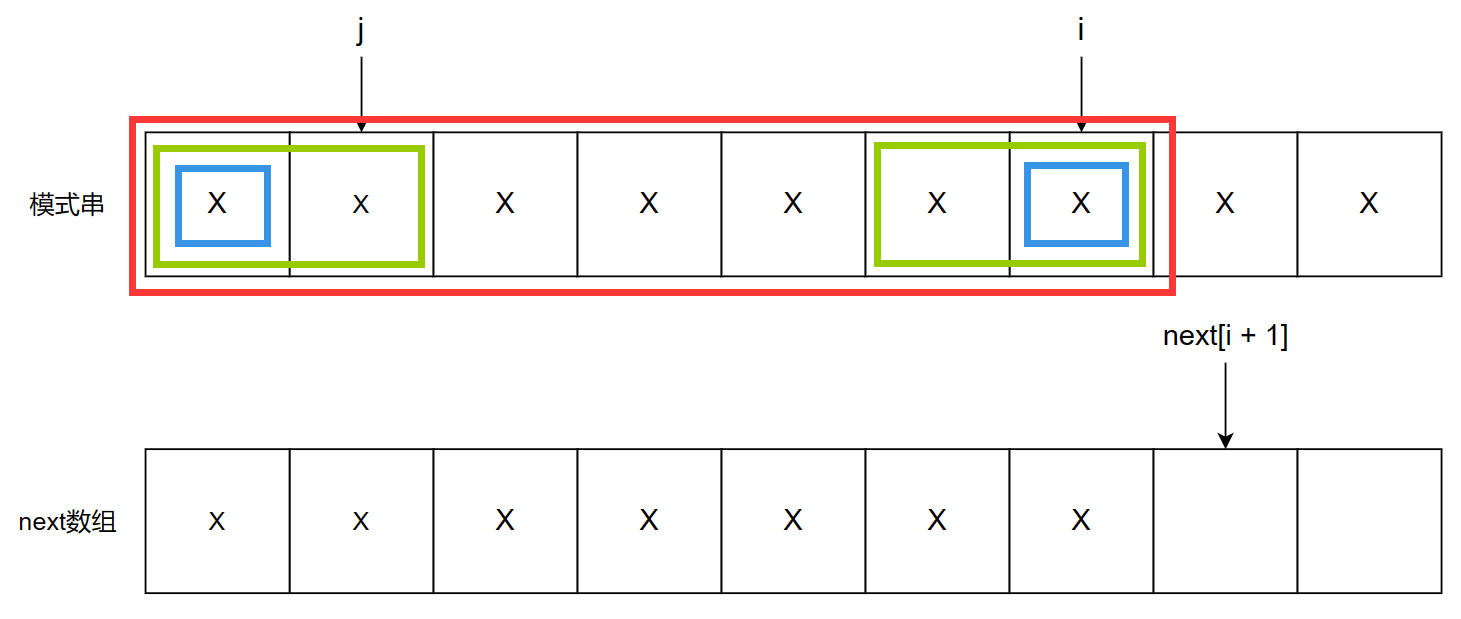
图中绿框的部分就是上一次循环比较的前缀,假设蓝框部分该前缀内的重合前后缀,当前循环执行 j = next[j] 后,在下一次循环中,我们比较 p[i] 和 p[j],若 p[i] = p[j],那么绿框部分就是当前红框子串的重合前后缀(因为蓝框部分重合,下一个字符还相等,那么继续重合)
Case3:j = -1
结合前面的讲解,这种情况应该很好理解了。
当 i 刚开始遍历时,i = 0,p[0, i] 只有一个字符,自然重合前后缀长度为 0,next[1] = j + 1 = 0
之后就是 j 回退到退无可退时,前缀没有重合的前后缀了,那么重合前后缀的长度自然也是 0,next[i] = j + 1 = 0
KMP 匹配
匹配算法相比 next 数组生成算法更加直观一些,我们直接开始算法过程
测试用例:p = "abac", s = "abaababac"
生成的 next = {-1, 0, 0, 1}
1 | int kmp(string& s, string& p) { |
-
i = 0, j = 0s[i] = p[j] = a, i++, j++
-
i = 1, j = 1s[i] = p[j] = b, i++, j++
-
i = 2, j = 2s[i] = p[j] = a, i++, j++
-
i = 3, j = 3s[i] = a, p[j] = c, j = next[3] = 1
-
i = 3, j = 1s[i] = a, p[j] = b, j = next[1] = 0
-
i = 3, j = 0s[i] = a, p[j] = a, i++, j++
-
i = 4, j = 1s[i] = b, p[j] = b, i++, j++
-
i = 5, j = 2s[i] = a, p[j] = a, i++, j++
-
i = 6, j = 3s[i] = b, p[j] = c, j = next[3] = 1
-
i = 6, j = 1s[i] = b, p[j] = b, i++, j++
-
i = 7, j = 2s[i] = a, p[j] = a, i++, j++
-
i = 8, j = 3s[i] = c, p[j] = c, i++, j++
-
i = 9, j = 4退出循环,j == p_len 成功匹配,第一个匹配的下标为 i - j
上述过程的正向比较很好理解,关键在于 j = next[j] 回退这一步,与之前 next 数组的生成有异曲同工之妙
我们来看过程中的第 9 步,如下图所示
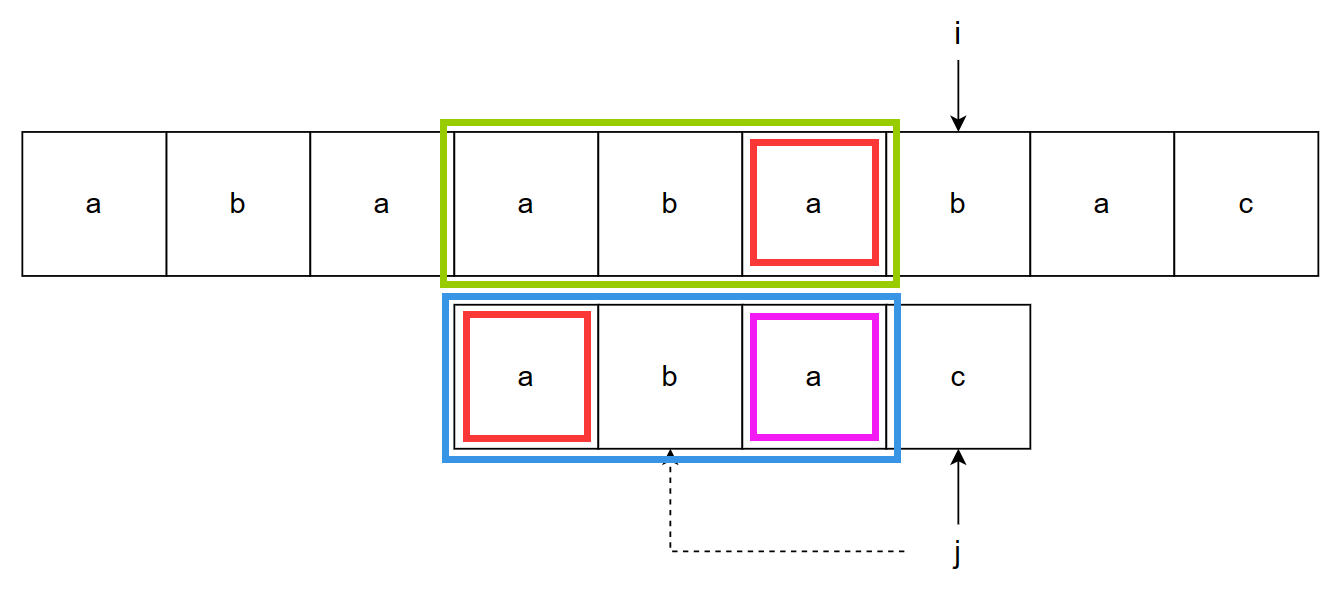
上图中 s[i] 和 p[j] 不匹配时,前面的部分是比较过且匹配的,此时考虑 next[j] 表示的模式子串(蓝框部分)和对应的匹配子串(绿框部分),模式子串的重合前后缀的长度就是 next[j] 的值,next[3] = 1,则图中左下红框部分是模式子串的重合前缀,紫框部分就是与它重合的后缀,同时由于模式子串与匹配子串相等(绿框部分和蓝框部分相同),所以两个子串的重合后缀相等(紫框部分和右上红框部分相等),最终得到模式子串的重合前缀和匹配子串的重合后缀相等(两个红框部分相等)。
令 j = next[j],得到重合前缀的下一个字符位置,下次从该位置开始比较,从而跳过之前重合的部分,这是 KMP 匹配的精髓
KMP 的应用
生成 next 数组算法在 LeetCode 459 题有一个应用(459. 重复的子字符串 - 力扣(LeetCode))
题目为给定一个非空的字符串 s,检查是否可以通过由它的一个子串重复多次构成
对于任意由子串重复多次构成的字符串,它必然有重合的前后缀,这是第一个必要条件,我们使用 next 数组来判断这个必要条件,若整个字符串的最长重合前后缀长度不为 0,则存在重合前后缀
通过上述讲解我们知道 next[i] 表示 p[0, i - 1] 的最长重合前后缀长度,那么我们想得到整个字符串的最长重合前后缀长度,就是求 next[len](len 为整个字符串长度)。这里相对原来的算法,我们需要把循环条件改为 i < p.size(),多遍历最后一个字符,我们要求整个字符串的前后缀,自然要包含所有的字符,下面是这一部分的代码
1 | // 生成next数组 |
我们已经判断了字符串中是否有重复的子串,现在来判断字符串是否是这个子串重复构成的
比较直接的想法就是求出整个字符串中重复的子串,然后遍历比较,但有更简单的做法。如果一个字符串是这个子串重复构成的,那么字符串的长度一定是子串长度的整数倍,这个就是判定重复构成的第二个必要条件。
这样就够了吗?这样确实够了,这里实际上运用到了 next 数组的性质,next 数组的值表示的子串是最长的重合前后缀,我们使用 next 数组求出这个重复子串的长度,举两个例子,输入 s1 = "abababab" 和 s2 = "ababcdab"
显然两个串的长度相等,s1 符合题目要求,s2 不符合要求。我们考虑这两个串的最长重合前后缀,s1 的最长重合前后缀是“ababab”,s2 的最长重合前后缀是“ab”,若直接使用这个最长前后缀的长度判断它是否被字符串长度整除,那么 s1 会被判为 false,s2 判为 true,这明显不符合题目要求。实际上只需要用字符串长度减去最长前后缀长度就可以得到重复的子串长度,妙就妙在这一点对于符合重复构成的字符串都是满足的,而其他字符串都是不满足的。
下面给出解法的完整代码
1 | // 生成next数组 |
结语
KMP 匹配的代码还是比较难理解的,其中关键是弄清 i 和 j 什么时候表示索引,什么时候表示长度,其次是要有递归的思想,理解 j 回退的原理,这两点弄清楚,KMP 算法就算掌握了
在理解 next 数组的基础上,可以灵活改变算法,用它求出我们想要的子串的最长重合前后缀,再利用最长重合前后缀的性质进行应用


