LLM开发者教程——LangChain
基本概念
LangChain是一个用于开发基于LLM应用的框架,LangChain由以下包构成
- langchain-core:包含核心组件
- langchain:包含了通用的模型、链等组件
- langchain-community:由社区维护,包含第三方集成
- langchain-*:langchain将一些流行的集成,如openai,单独拆分到各自的包中
- langgraph:提供了用于创建常见类型代理的高级接口,以及用于组合自定义流程的低级API
- langserve:一个将LangChain链部署为REST API的包
- LangSmith:一个开发者平台,让你能够调试、测试、评估和监控LLM应用程序
LCEL
langchain表达式(LCEL),langchain通过重载__or__运算符和__ror__运算符实现了通过|来组合各个组件,如模板、模型、解析器等
e.g.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
# 定义提示模板
prompt = ChatPromptTemplate.from_template("回答用户关于{topic}的问题:{question}")
# 初始化模型
model = ChatOpenAI()
# 定义输出解析器
output_parser = StrOutputParser()
# 使用管道符组合链:提示模板 → 模型 → 输出解析器
chain = prompt | model | output_parser
# 调用链并输出结果
result = chain.invoke({"topic": "科技", "question": "量子计算的未来发展"})
print(result) # 输出解析后的字符串结果
Runnable
langchain中定义了Runnable协议,许多组件(如模板、LLM、解析器、检索器等)都实现了Runnable协议,langchain基于Runnable协议来构建LCEL链
Runnable类是langchain链的核心类,langchain核心类图如下
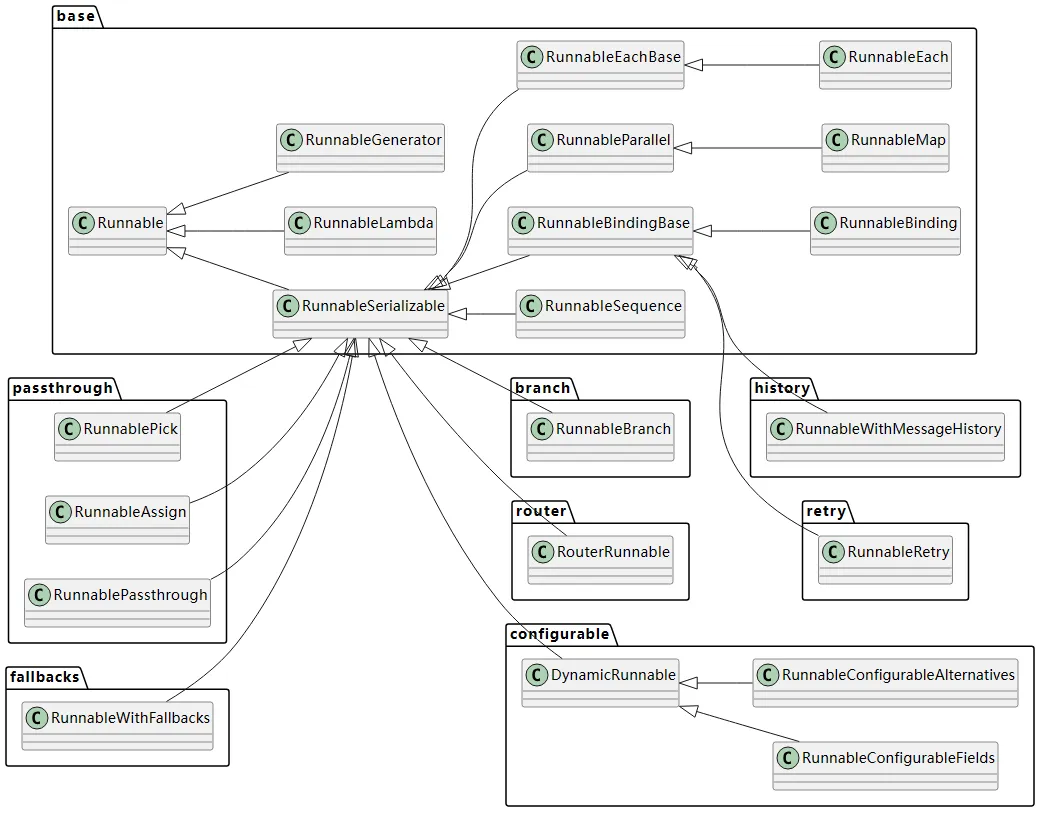
Runnable类部分定义如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
class Runnable(Generic[Input, Output], ABC):
"""A unit of work that can be invoked, batched, streamed, transformed and composed.
Key Methods
===========
* invoke/ainvoke: Transforms a single input into an output.
* batch/abatch: Efficiently transforms multiple inputs into outputs.
* stream/astream: Streams output from a single input as it's produced.
* astream_log: Streams output and selected intermediate results from an input.
"""
def __or__() -> RunnableSerializable[Input, Other]:
"""Compose this runnable with another object to create a RunnableSequence."""
return RunnableSequence(self, coerce_to_runnable(other))
def __ror__() -> RunnableSerializable[Other, Output]:
"""Compose this runnable with another object to create a RunnableSequence."""
return RunnableSequence(coerce_to_runnable(other), self)
Runnable类包含的核心方法如下,以a开头的方法为异步方法
invoke/ainvoke:简单地将输入转换为输出,即调用batch/abatch:将多个输入转换为输出stream/astream:流式调用astream_log:在异步流式调用的过程返回中间结果
runnables包
runnables包中包含了LCEL链流程控制的Runnable实现类
RunnablePassthrough
RunnablePassthrough直接将输入传递到输出,不作任何处理,适用于需要向原始输入添加额外信息的情况
RunnableSequence
RunnableSequence是最重要的一个类,可以直接创建可运行的对象,并且将对象的输出作为下一个对象的输入
使用RunnableLambda类,可以直接将一个函数转换为RunnableSequence
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from langchain_core.runnables import RunnableLambda
def add_one(x: int) -> int:
return x + 1
def mul_two(x: int) -> int:
return x * 2
runnable_1 = RunnableLambda(add_one)
runnable_2 = RunnableLambda(mul_two)
sequence = runnable_1 | runnable_2
# Or equivalently:
# sequence = RunnableSequence(first=runnable_1, last=runnable_2)
sequence.invoke(1)
await sequence.ainvoke(1)
sequence.batch([1, 2, 3])
await sequence.abatch([1, 2, 3])
RunnableParallel
支持langchain的并行执行分支,将一个输入分发到独立的多个串行分支中进行处理,返回一个结果map
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
from langchain_core.runnables import RunnableLambda
def add_one(x: int) -> int:
return x + 1
def mul_two(x: int) -> int:
return x * 2
def mul_three(x: int) -> int:
return x * 3
runnable_1 = RunnableLambda(add_one)
runnable_2 = RunnableLambda(mul_two)
runnable_3 = RunnableLambda(mul_three)
sequence = runnable_1 | { # this dict is coerced to a RunnableParallel
"mul_two": runnable_2,
"mul_three": runnable_3,
}
sequence.invoke(1) # {"mul_two": 4, "mul_three": 6}
RunnableBranch
RunnableBranch实现了分支判断
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
from langchain_core.runnables import RunnableBranch
branch = RunnableBranch(
(lambda x: isinstance(x, str), lambda x: x.upper()),
(lambda x: isinstance(x, int), lambda x: x + 1),
(lambda x: isinstance(x, float), lambda x: x * 2),
lambda x: "goodbye",
)
branch.invoke("hello") # "HELLO"
branch.invoke(None) # "goodbye"
# 等同于以下语句
def branch(x):
if isinstance(x, str):
return x.upper()
elif isinstance(x, int):
return x + 1
elif isinstance(x, float):
return x * 2
else:
return "goodbye"
RunnableEach
RunnableEach用于接受多个输入,将每个输入逐个输入到链中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
from langchain_core.runnables.base import RunnableEach
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
prompt = ChatPromptTemplate.from_template("Tell me a short joke about{topic}")
model = ChatOpenAI()
output_parser = StrOutputParser()
runnable = prompt | model | output_parser
runnable_each = RunnableEach(bound=runnable) # bound参数绑定处理输入的链
output = runnable_each.invoke([
{'topic':'Computer Science'},
{'topic':'Art'},
{'topic':'Biology'}
]) # 每个元素都作为链的输入
print(output) # noqa: T201
基本组件
组件部分用法详见:使用指南
聊天模型
使用一系列消息作为输入并返回聊天消息作为输出的语言模型,聊天模型支持为对话消息分配不同的角色,有助于区分来自AI、用户和系统消息等指令的消息
聊天模型类以Chat开头,与基础模型区分,langchain也支持基础模型,但通常模型较旧,因此通常只使用聊天模型
构建聊天模型通常有以下参数
model:模型名称temperature:采样温度timeout:请求超时max_tokens:生成的最大令牌数stop:默认停止序列max_retries:请求重试的最大次数api_key:大模型供应商的API密钥base_url:发送请求的端点
消息
聊天模型交互的内容通过消息封装,主要有SystemMessage、HumanMessage、AIMessage、ToolMessage,每种消息都有role和content两个属性
HumanMessage:输入promptAIMessage:输出completion,其中的tool_calls属性表示模型调用工具的决策,为一个ToolCall列表,每个ToolCall包含以下属性name:应该被调用的工具的名称args:工具的参数id:工具调用id
SystemMessage:系统promptToolMessage:包含工具调用的结果,在消息列表中只能出现在填充了tool_calls属性的AIMessage之后,该消息包含以下重要属性content:返回给模型的文本内容,用于解释工具执行的结果或上下文tool_call_id:工具调用id,与ToolCall.id对应artifact:工具执行的具体结果(如文件、自定义对象等),这些结果不应该直接传递给模型,应该传递到下游组件进行处理
多轮对话中,消息的基本传递流程如下
graph LR
User(用户);
Dev(开发);
Model(聊天模型);
User-->|用户输入|Dev;
Dev-->|SystemMessage/HumanMessage|Model;
Model-->|AIMessage|Dev;
提示词模板
构建提示词模板通过PromptTemplate类来实现,在模板中通过{variable}定义插值的变量,在调用模板时传入一个字典,其中包含参数键值对,如{"variable": value}
通过字符串创建提示词模板
1
2
3
4
5
from langchain_core.prompts import PromptTemplate
prompt_template = PromptTemplate.from_template("Tell me a joke about {topic}")
prompt_template.invoke({"topic": "cats"})
对于聊天消息,消息中包含role字段,表示角色名,创建方式与PromptTemplate相同
1
2
3
4
5
6
from langchain.prompts import ChatMessagePromptTemplate
template = "May the {subject} be with you"
chat_message_prompt = ChatMessagePromptTemplate.from_template(role="Jedi", template=template)
chat_message_prompt.format(subject="force")
在构建消息列表提示词时,需要使用ChatPromptTemplate类
1
2
3
4
5
6
7
8
9
from langchain_core.prompts import ChatPromptTemplate
prompt_template = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant"),
("user", "Tell me a joke about {topic}")
])
# format_prompt作用与invoke相同
prompt_template.invoke({"topic": "cats"})
使用消息占位符可以将消息插入到特定位置
1
2
3
4
5
6
7
8
9
10
11
12
13
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import HumanMessage
prompt_template = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant"),
MessagesPlaceholder("msgs"),
("placeholder", "{msgs1}") # 隐式消息占位
])
prompt_template.invoke({
"msgs": [HumanMessage(content="hi!")],
"msgs1": [HumanMessage(content="test")]
})
输出解析器
输出解析器获取模型的输出并将其转换为更适合下游任务的格式
langchain支持以下解析器
| 名称 | 支持流式处理 | 有格式说明 | 输入类型 | 输出类型 | 描述 |
|---|---|---|---|---|---|
| JSON | ✅ | ✅ | str、消息 | JSON对象 | 返回指定的JSON对象。您可以指定一个Pydantic模型,它将返回该模型的JSON。可能是获取不使用函数调用的结构化数据的最可靠输出解析器。 |
| XML | ✅ | ✅ | str、消息 | dict | 返回标签的字典。当需要XML输出时使用。与擅长编写XML的模型(如Anthropic的模型)一起使用。 |
| CSV | ✅ | ✅ | str、消息 | List[str] | 返回以逗号分隔的值的列表。 |
| OutputFixing | str、消息 | 包装另一个输出解析器。如果该输出解析器出错,则会将错误消息和错误输出传递给大型语言模型,并请求其修复输出。 | |||
| RetryWithError | str、消息 | 包装另一个输出解析器。如果该输出解析器出错,则会将原始输入、错误输出和错误消息传递给大型语言模型,并请求其修复。与OutputFixingParser相比,这个还会发送原始说明。 | |||
| Pydantic | ✅ | str、消息 | pydantic.BaseModel | 接受用户定义的Pydantic模型,并以该格式返回数据。 | |
| YAML | ✅ | str、消息 | pydantic.BaseModel | 接受用户定义的Pydantic模型,并以该格式返回数据。使用YAML进行编码。 | |
| PandasDataFrame | ✅ | str、消息、dict | 对于使用pandas DataFrame进行操作非常有用。 | ||
| 枚举 | ✅ | str、消息、Enum | 将响应解析为提供的枚举值之一。 | ||
| 日期时间 | ✅ | str、消息、datetime.datetime | 将响应解析为日期时间字符串。 | ||
| 结构化 | ✅ | str、消息、Dict[str, str] | 一种输出解析器,返回结构化信息。它的功能不如其他输出解析器强大,因为它只允许字段为字符串。当您使用较小的LLM时,这可能会很有用。 |
文档
langchain将文本内容封装成一个个文档对象(Document对象),可以从多种数据源中加载文档,如PDF、CSV、JSON、Web页面等
Document对象包含两个属性
page_content: str:此文档的内容。目前仅为字符串metadata: dict:与此文档相关的任意元数据,可以跟踪文档ID、文件名等
文档对象通过文档加载器获取,每个文档加载器都有一个load方法,调用该方法获取文档对象
1
2
3
4
5
6
from langchain_community.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(
... # <-- Integration specific parameters here
)
data = loader.load()
获取文档对象后,需要对文档进行切分,以适应模型的max_tokens,langchain中提供了多种文档分割器,基本工作原理如下
- 将文本拆分成小的、语义上有意义的块(通常是句子),可以自定义文本的拆分方式
- 开始将这些小块组合成一个更大的块,直到达到某个大小(通过某个函数来衡量),可以自定义块大小的测量
- 一旦达到该大小,将该块作为独立的文本片段,然后开始创建一个新的文本块,并保持一些重叠(以保持块之间的上下文)
对于通用文本,langchain中通常使用RecursiveCharacterTextSplitter进行文本分割,它根据指定的字符列表进行分割,默认字符列表为['\n\n', '\n', ' ', ''],根据字符数确定块大小
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Load example document
with open("state_of_the_union.txt") as f:
state_of_the_union = f.read()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=100, # 块大小的最大值
chunk_overlap=20, # 块重叠的大小
length_function=len, # 确定块大小的函数
is_separator_regex=False, # 分隔符列表是否应被解释为正则表达式
)
texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
print(texts[1])
对于没有词边界的语言(如中文)进行文本分割,需要添加一些分隔符
1
2
3
4
5
6
7
8
9
10
11
text_splitter = RecursiveCharacterTextSplitter(
separators=[
"\n\n", "\n", " ", ".", ",", "",
"\u200b", # Zero-width space
"\uff0c", # Fullwidth comma
"\u3001", # Ideographic comma
"\uff0e", # Fullwidth full stop
"\u3002", # Ideographic full stop
],
# Existing args
)
聊天历史存储
聊天历史存储提供了访问聊天历史的能力,可以将早期对话引入当前对话,langchain中实现了聊天历史存储(截止v0.2),在langchain的最新版本中推荐使用langgraph提供的持久化能力
RunnableWithMessageHistory类可以包装任何链,跟踪链的输入和输出,并将它们作为消息附加到消息存储
消息存储通过BaseChatMessageHistory类实现,langchain内置了多种类型的实现类,如SQL、Redis等

构造RunnableWithMessageHistory需要以下参数
chain:被包装的链get_session_history:一个函数,函数接受sessihon_id字符串,返回BaseChatMessageHistory类型对象input_messages_key:当链的输入为一个字典时,指定该参数为值是消息列表的键output_messages_key:当链的输出为一个字典时,指定该参数为值是消息列表的键history_messages_key:当链的输入为一个字典时,指定该参数,以该参数为键保存历史消息history_factory_config:该参数接受ConfigurableFieldSpec对象列表,配置get_session_history的参数
e.g.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_community.chat_models import ChatZhipuAI
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
stlore = {} # 使用全局存储
def get_by_session_id(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
prompt = ChatPromptTemplate.from_messages([
("system", "You're an assistant who's good at {ability}"),
MessagesPlaceholder(variable_name="history"), # 历史记录
("human", "{question}"), # 消息列表
])
chain = prompt | model
chain_with_history = RunnableWithMessageHistory(
chain,
get_by_session_id,
input_messages_key="question", # 链的输入中值为消息列表的键
history_messages_key="history", # 链的输入中值为历史记录的键
)
# 输入消息列表和其他值,config参数指定传入get_by_session_id函数的参数
result = chain_with_history.invoke(
{"question": "What does cosine mean?", "ability": "math"},
config={"configurable": {"session_id": "foo"}}
)
当get_session_history函数接受多个参数时,需要设置history_factory_config,设置参数定义
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
store = {}
def get_session_history(user_id: str, conversation_id: str) -> BaseChatMessageHistory:
if (user_id, conversation_id) not in store:
store[(user_id, conversation_id)] = ChatMessageHistory()
return store[(user_id, conversation_id)]
with_message_history = RunnableWithMessageHistory(
chain,
get_session_history=get_session_history,
input_messages_key="question",
history_messages_key="history",
history_factory_config=[
ConfigurableFieldSpec(
id="user_id",
annotation=str,
name="User ID",
description="Unique identifier for the user.",
default="",
is_shared=True,
),
ConfigurableFieldSpec(
id="conversation_id",
annotation=str,
name="Conversation ID",
description="Unique identifier for the conversation.",
default="",
is_shared=True,
),
],
)
向量存储与检索
langchain支持将文本嵌入为向量,通过向量之间的距离计算文本的相似度,实现相似文本搜索的功能,该功能主要由嵌入模型、向量存储和检索器实现
嵌入模型
嵌入模型将文本转换为包含语义的向量,从而进行诸如搜索其他在意义上最相似的文本等操作
langchain中使用Embeddings类封装不同嵌入模型供应商(如OpenAI、Hugging Face等)的接口
嵌入模型包含两个方法
embed_documents:用于嵌入文档,参数为一个字符串列表embed_query:用于嵌入查询,参数为单个文本
1
2
3
4
5
6
7
8
embeddings = embeddings_model.embed_documents([
"Hi there!",
"Oh, hello!",
"What's your name?",
"My friends call me World",
"Hello World!"
])
len(embeddings), len(embeddings[0]) # (5, 1536)
向量存储
存储和搜索非结构化数据的最常见方法之一是将其嵌入并存储生成的嵌入向量,然后在查询时嵌入非结构化查询并检索与嵌入查询最相似的嵌入向量
langchain中集成了一些优秀的开源向量存储,主要有Chroma、FAISS、Lance
1
2
3
from langchain_chroma import Chroma
db = Chroma.from_documents(documents, OpenAIEmbeddings())
所有的向量存储都包含similarity_search方法,用于文本相似性搜索
1
2
3
query = "What did the president say about Ketanji Brown Jackson"
docs = db.similarity_search(query) # 返回最相似的Document对象
print(docs[0].page_content)
使用similarity_search_by_vector方法可以直接使用向量进行相似性搜索
1
2
3
embedding_vector = OpenAIEmbeddings().embed_query(query)
docs = db.similarity_search_by_vector(embedding_vector)
print(docs[0].page_content)
向量存储的所有操作方法都有异步版本,以a开头
1
docs = await db.asimilarity_search(query)
检索器
检索器是搜索操作更加抽象的接口,给定非结构化的查询,返回文档,检索器不止可以从向量存储中搜索,也可以从其他数据源中搜索
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
# 加载文档
loader = TextLoader("state_of_the_union.txt")
documents = loader.load()
# 文本分割
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# 创建向量存储
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(texts, embeddings)
# 检索,进行相似性搜索
retriever = vectorstore.as_retriever()
docs = retriever.invoke("what did the president say about ketanji brown jackson?")
创建检索器时,可以进行一些配置
1
2
3
4
5
6
7
8
9
# 指定使用最大边际相关性搜索
retriever = vectorstore.as_retriever(search_type="mmr")
# 指定使用相似性得分阈值搜索
retriever = vectorstore.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={"score_threshold": 0.5}
)
# 指定返回文档数量
retriever = vectorstore.as_retriever(search_kwargs={"k": 1})
工具
工具(Tool)是一种输入由模型产生,输出返回给模型的程序
一个工具由以下属性组成
name:工具名称description:工具的描述args_schema:通过pydantic.BaseModel定义工具输入return_direct:仅与代理相关。当为True时,在调用给定工具后,代理将停止并直接将结果返回给用户- 可执行对象
工具设计原则:工具尽量具有明确的名称、描述和参数列表,功能单一的工具相比复杂工具更容易被模型使用
创建工具
langchain支持通过函数、Runnable、BaseTool三种方式来创建工具
从函数创建工具
从函数创建工具,使用@tool装饰器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
from langchain_core.tools import tool
@tool
def multiply(a: int, b: int) -> int:
"""Multiply two numbers."""
return a * b
# 异步版本
@tool
async def amultiply(a: int, b: int) -> int:
"""Multiply two numbers."""
return a * b
# @tool支持解析注释、嵌套模式
@tool
def multiply_by_max(
a: Annotated[str, "scale factor"],
b: Annotated[List[int], "list of ints over which to take maximum"],
) -> int:
"""Multiply a by the maximum of b."""
return a * max(b)
print(multiply.name) # multiply
print(multiply.description) # Multiply two numbers.
print(multiply.args) # {'a': {'title': 'A', 'type': 'integer'}, 'b': {'title': 'B', 'type': 'integer'}}
也可直接在@tool中定义工具
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from pydantic import BaseModel, Field
# 通过Pydantic定义,也可通过TypedDict定义
class CalculatorInput(BaseModel):
a: int = Field(description="first number")
b: int = Field(description="second number")
@tool("multiplication-tool", args_schema=CalculatorInput, return_direct=True)
def multiply(a: int, b: int) -> int:
"""Multiply two numbers."""
return a * b
print(multiply.name)
print(multiply.description)
print(multiply.args)
print(multiply.return_direct)
使用StructuredTool类可以提供更多的配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
class CalculatorInput(BaseModel):
a: int = Field(description="first number")
b: int = Field(description="second number")
def multiply(a: int, b: int) -> int:
"""Multiply two numbers."""
return a * b
async def amultiply(a: int, b: int) -> int:
"""Multiply two numbers."""
return a * b
calculator = StructuredTool.from_function(
func=multiply,
name="Calculator",
description="multiply numbers",
args_schema=CalculatorInput,
return_direct=True,
coroutine=amultiply
)
print(calculator.invoke({"a": 2, "b": 3}))
print(calculator.name)
print(calculator.description)
print(calculator.args)
从Runnable创建工具
对于任意的Runnable实现类,可以通过as_tool方法将其转换为一个工具
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from langchain_core.language_models import GenericFakeChatModel
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages(
[("human", "Hello. Please respond in the style of {answer_style}.")]
)
# Placeholder LLM
llm = GenericFakeChatModel(messages=iter(["hello matey"]))
chain = prompt | llm | StrOutputParser()
as_tool = chain.as_tool(
name="Style responder",
description="Description of when to use tool."
)
as_tool.args
从BaseTool创建工具
BaseTool提供了定义工具的最大控制
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
from typing import Optional, Type
from langchain_core.callbacks import (
AsyncCallbackManagerForToolRun,
CallbackManagerForToolRun,
)
from langchain_core.tools import BaseTool
from pydantic import BaseModel
# 定义args_schema
class CalculatorInput(BaseModel):
a: int = Field(description="first number")
b: int = Field(description="second number")
# BaseTool是一个Pydantic类,因此属性都需要类型标记
class CustomCalculatorTool(BaseTool):
name: str = "Calculator"
description: str = "useful for when you need to answer questions about math"
args_schema: Type[BaseModel] = CalculatorInput
return_direct: bool = True
# 同步执行
def _run(
self, a: int, b: int, run_manager: Optional[CallbackManagerForToolRun] = None
) -> str:
"""Use the tool."""
return a * b
# 异步执行
async def _arun(
self,
a: int,
b: int,
run_manager: Optional[AsyncCallbackManagerForToolRun] = None,
) -> str:
"""Use the tool asynchronously."""
# If the calculation is cheap, you can just delegate to the sync implementation
# as shown below.
# If the sync calculation is expensive, you should delete the entire _arun method.
# LangChain will automatically provide a better implementation that will
# kick off the task in a thread to make sure it doesn't block other async code.
return self._run(a, b, run_manager=run_manager.get_sync())
使用异步工具
在创建异步工具时,需要注意以下事项
- LangChain默认提供异步实现
- 若在异步代码库中工作,应该创建异步工具而不是同步工具,以避免因该线程而产生小的开销
- 若需要同步和异步实现,使用
StructuredTool或从BaseTool子类化 - 同时实现同步和异步时,若同步代码运行速度较快,应覆盖默认异步实现并直接调用同步函数,否则应使用默认异步实现
- 不能将同步
invoke与异步工具一起使用
处理工具异常
langchain中使用工具时产生异常,将抛出ToolException,可以设置工具的handle_tool_error属性来控制如何处理异常
- 当
handle_tool_error设置为True时,使用默认实现,返回一个错误信息字符串 - 当
handle_tool_error设置为字符串时,将字符串作为错误信息返回 - 当
handle_tool_error设置为函数时,函数作为异常处理器,接受一个ToolException类型的参数,返回错误信息字符串
返回工具的具体产物
在模型调用工具时,通常工具返回的是一个文本字符串,若需要返回工具产生的文件、自定义对象等产物,则需要工具返回ToolMessage,其中的content属性包含了返回给模型的文本字符串,artifact属性包含了工具输出的具体产物
返回ToolMessage,需要进行以下步骤
- 设置工具的
response_format属性为"content_and_artifact",同时在工具执行代码中返回一个元组,其中第一个元素为content,第二个元素为artifact - 若手动调用工具,则需要传入完整的
ToolCall定义
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import random
from typing import List, Tuple
from langchain_core.tools import tool
@tool(response_format="content_and_artifact")
def generate_random_ints(min: int, max: int, size: int) -> Tuple[str, List[int]]:
"""Generate size random ints in the range [min, max]."""
array = [random.randint(min, max) for _ in range(size)]
content = f"Successfully generated array of {size} random ints in [{min}, {max}]."
return content, array
# 传入ToolCall完整定义
generate_random_ints.invoke({
"name": "generate_random_ints",
"args": {"min": 0, "max": 9, "size": 10},
"id": "123", # required
"type": "tool_call", # required
})
与聊天模型交互
通过聊天模型产生工具参数
首先需要使用聊天模型,从查询文本字符串提取出工具调用的参数,支持工具调用的模型包含一个bind_tools方法,接受一个工具args_schema的列表
调用设置了工具的聊天模型后,输出的AIMessage中的tool_calls属性会包含可被输入到工具的参数,若模型输出解析失败,则记录在invalid_tool_cahlls属性中,使用InvalidToolCall类封装
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
from pydantic import BaseModel, Field
class AddArgs(BaseModel):
"""Add two integers."""
a: int = Field(..., description="First integer")
b: int = Field(..., description="Second integer")
class MultiplyArgs(BaseModel):
"""Multiply two integers."""
a: int = Field(..., description="First integer")
b: int = Field(..., description="Second integer")
# 可传入参数模型类也可直接传入工具函数,若传入dict,则需要符合openai、Anthropic格式
llm_with_tools = llm.bind_tools([AddArgs, MultiplyArgs])
query = "What is 3 * 12?"
llm_with_tools.invoke(query) # 返回AIMessage,在tool_calls中包含工具的参数
使用PydanticToolsParser解析器,可以直接从AIMessage中提取参数,转换为Pydantic模式类
1
2
3
4
from langchain_core.output_parsers import PydanticToolsParser
chain = llm_with_tools | PydanticToolsParser(tools=[add, multiply])
chain.invoke(query)
工具调用
通过聊天模型产生参数后,手动调用工具执行,传入ToolCall时,工具可返回一个ToolMessage,可直接添加到消息列表中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
from langchain_core.tools import tool
@tool
def add(a: int, b: int) -> int:
"""Adds a and b."""
return a + b
@tool
def multiply(a: int, b: int) -> int:
"""Multiplies a and b."""
return a * b
tools = {"AddArgs": add, "MultiplyArgs": multiply}
for tool_call in ai_msg.tool_calls:
selected_tool = tools[tool_call["name"].lower()]
# tool_call符合ToolCall模型
# 此处将整个tool_call传入工具,工具才能返回ToolMessage,传入args只能返回结果
tool_msg = selected_tool.invoke(tool_call)
messages.append(tool_msg)
将结果返回给模型
将包含ToolMessage的消息列表返回给模型,模型将使用ToolMessage中的content属性
1
llm_with_tools.invoke(messages)
聊天模型与工具的交互如下
sequenceDiagram
participant Model as 聊天模型;
participant Dev as 开发;
participant Tool as 工具;
Dev->>Model:带有工具参数的prompt;
Model->>Dev:从prompt提取的工具参数;
Dev->>Tool:调用工具;
Tool->>Dev:返回ToolMessage;
Dev->>Model:将ToolMessage返回聊天模型;
第三方集成
langchain中已经内置了一些第三方集成工具,可以直接调用
e.g. 调用Wikipedia工具
1
2
3
4
5
6
7
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
api_wrapper = WikipediaAPIWrapper(top_k_results=1, doc_content_chars_max=100)
tool = WikipediaQueryRun(api_wrapper=api_wrapper)
print(tool.invoke({"query": "langchain"}))
回调
langchain支持在LLM应用程序的各个阶段进行挂钩,可以通过使用API中可用的callbacks参数来订阅回调事件,该参数接受一个回调处理器对象的列表
定义回调处理器
回调处理器分为同步和异步两个版本,同步回调处理器需要实现BaseCallbackHandler接口,异步回调处理器需要实现AsyncCallbackHandler接口,接口中包含多个回调事件方法,重写需要的回调事件方法
| 事件 | 事件触发 | 关联方法 |
|---|---|---|
| 聊天模型开始 | 当聊天模型开始时 | on_chat_model_start |
| LLM开始 | 当LLM开始时 | on_llm_start |
| LLM新令牌 | 当LLM或聊天模型发出新令牌时 | on_llm_new_token |
| LLM 结束 | 当一个大型语言模型或聊天模型结束 | on_llm_end |
| LLM 错误 | 当一个大型语言模型或聊天模型出错 | on_llm_error |
| 链开始 | 当一个链开始运行 | on_chain_start |
| 链结束 | 当一个链结束 | on_chain_end |
| 链错误 | 当一个链出错 | on_chain_error |
| 工具开始 | 当一个工具开始运行 | on_tool_start |
| 工具结束 | 当一个工具结束 | on_tool_end |
| 工具错误 | 当一个工具出错 | on_tool_error |
| 代理动作 | 当一个代理采取行动 | on_agent_action |
| 代理结束 | 当一个代理结束 | on_agent_finish |
| 检索器开始 | 当检索器开始时 | on_retriever_start |
| 检索器结束 | 当检索器结束时 | on_retriever_end |
| 检索器错误 | 当检索器发生错误时 | on_retriever_error |
| 文本 | 当任意文本被运行时 | on_text |
| 重试 | 当重试事件被触发时 | on_retry |
e.g.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
from typing import Any, Dict, List
from langchain_core.callbacks import BaseCallbackHandler
from langchain_core.messages import BaseMessage
from langchain_core.outputs import LLMResult
class LoggingHandler(BaseCallbackHandler):
def on_chat_model_start(
self, serialized: Dict[str, Any], messages: List[List[BaseMessage]], **kwargs
) -> None:
print("Chat model started")
def on_llm_end(self, response: LLMResult, **kwargs) -> None:
print(f"Chat model ended, response: {response}")
def on_chain_start(
self, serialized: Dict[str, Any], inputs: Dict[str, Any], **kwargs
) -> None:
print(f"Chain {serialized.get('name')} started")
def on_chain_end(self, outputs: Dict[str, Any], **kwargs) -> None:
print(f"Chain ended, outputs: {outputs}")
设置回调
通常在以下位置设置回调
在最终调用
invoke方法时设置回调:回调将作用在每个组件上1 2 3 4 5 6 7
callbacks = [LoggingHandler()] llm = ChatAnthropic(model="claude-3-sonnet-20240229") prompt = ChatPromptTemplate.from_template("What is 1 + {number}?") chain = prompt | llm chain.invoke({"number": "2"}, config={"callbacks": callbacks}) # 设置回调
在组件的构造器中传入回调:回调仅作用在设置回调的组件上
1 2 3 4 5 6 7
callbacks = [LoggingHandler()] llm = ChatAnthropic(model="claude-3-sonnet-20240229", callbacks=callbacks) # 设置回调 prompt = ChatPromptTemplate.from_template("What is 1 + {number}?") chain = prompt | llm chain.invoke({"number": "2"})
在链的
with_config方法中传入回调:回调将作用在该链的组件中1 2 3 4 5 6 7 8 9
callbacks = [LoggingHandler()] llm = ChatAnthropic(model="claude-3-sonnet-20240229") prompt = ChatPromptTemplate.from_template("What is 1 + {number}?") chain = prompt | llm chain_with_callbacks = chain.with_config(callbacks=callbacks) # 设置回调 chain_with_callbacks.invoke({"number": "2"})