基本形式
对样本 x=(x1;x2;x3;...;xd),有
f(xi)=ωTx+b
其中 ω=(ω1;ω2;...;ωd)
线性回归
离散属性处理
- 具有序关系的属性可以连续化,如身高
- 不具有序关系的属性转化为 k 维向量
一元线性回归
对于一元线性回归
f(xi)=ωxi+b
使用均方误差来衡量 f(x) 与 y的差别,并使其最小化来求解模型的方法称为最小二乘法
最小二乘参数估计
E(ω,b)∂ω∂E(ω,b)∂b∂E(ω,b)=i=1∑m(f(xi)−yi)2=2(ωi=1∑mxi2−i=1∑m(yi−b)xi)=2(mb−i=1∑m(yi−ωxi))
令两个偏导为 0 可求得 ω 和 b 最优解
多元线性回归
对于多元线性回归
f(xi)=ωTxi+b
定义向量形式如下
Xω^y=⎣⎢⎢⎢⎢⎡x11x21⋮xm1x12x22⋮xm2⋯⋯⋱⋯x1dx2d⋮xmd11⋮1⎦⎥⎥⎥⎥⎤=⎣⎢⎢⎢⎢⎡x1Tx2T⋮xmT11⋮1⎦⎥⎥⎥⎥⎤=(ω,b)=(y1;y2;...;ym)
由最小二乘法有
E(ω^)∂ω∂E(ω^)=(y−Xω^)T(y−Xω^)=2XT(Xω^−y)
当 XTX 满秩时,令偏导为 0 有唯一解,也称为正规方程法
ω^=(XTX)−1XTy
当 XTX 不满秩时,存在多组解,由算法的归纳偏好决定输出哪一组解,通常引入正则化项
广义线性模型
y=g−1(ωTx+b)
其中函数 g(.) 单调可微,称为联系函数,可以理解为将线性模型的预测值与实际标记联系起来的函数
对数几率回归
对于二分类任务,使用线性模型需要将线性模型的输出值与分类联系起来
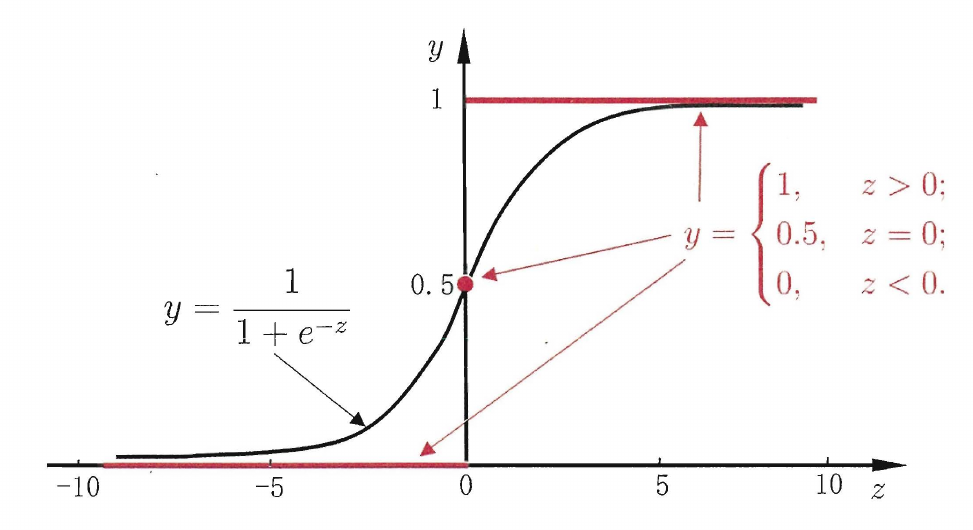
使用 sigmoid 函数作为联系函数
y=1+e−z1
sigmoid 函数将 (−∞,+∞) 映射到 (0,1) 之间
代入线性函数有
yln1−yy=1+e−(ωTx+b)1=ωT+b
其中 ln1−yy称为对数几率(logit),反映了正例的相对几率
将 y 重写为概率估计,通过极大似然估计可求解参数
p(y=1∣x)p(y=0∣x)=1+eωTx+beωTx+b=1+eωTx+b1
线性判别分析
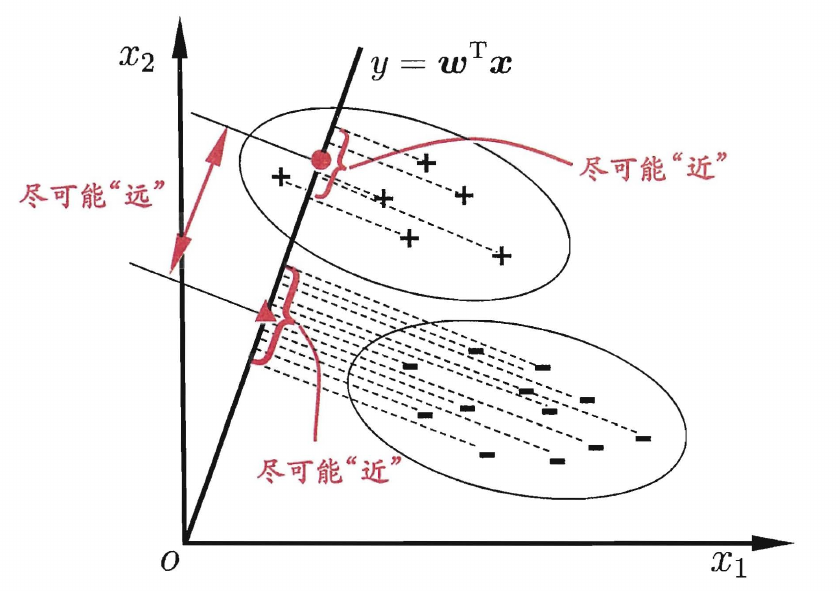
在二分类问题上,线性判别分析(LDA)通过将样本投影到一条直线上,同时使得相同类别的样本的投影点尽可能接近,而不同类别的样本的投影点尽可能远离,确定直线后,将新样本投影到该直线上,根据投影点的位置判定类别
LDA 的目标是使同类样本的投影点尽可能接近,则可以使同类样本投影点的协方差尽可能小,使不同的样本的投影点尽可能远离,则可以使类中心的距离尽可能大,用 μ0 和 μ1 表示两类样本的均值向量,Σ0 和 Σ1 表示两类样本的协方差矩阵,有最大化目标函数
J=ωT(Σ0+Σ1)ωωT(μ0−μ1)(μ0−μ1)Tω=ωTSωωωTSbω
多分类学习
对于多分类问题,通常是使用一些拆分策略,将其转换为多个二分类问题,通常有以下三种拆分策略
- 一对一(OvO):将 N 个类别两两配对,形成 N(N−1)/2 组二分类问题,最终结果取预测最多的类别
- 一对其余(OvR):将一个类别作为正例,其余类别作为反例,形成 N 个二分类问题
- 多对多(MvM):取多个类别作为正例,其他类别作为反例,通常使用纠错输出码(ECOC)拆分
ECOC 分为两步
- 编码:对 N 个类别做 M 次划分,划分出 M 个训练集,训练出 M 个分类器
- 解码:M 个分类器分别对测试样本分类,产生的预测标记组成一个编码,将这个编码与每个类别定义的编码进行比较,将其中距离最小的类别作为结果
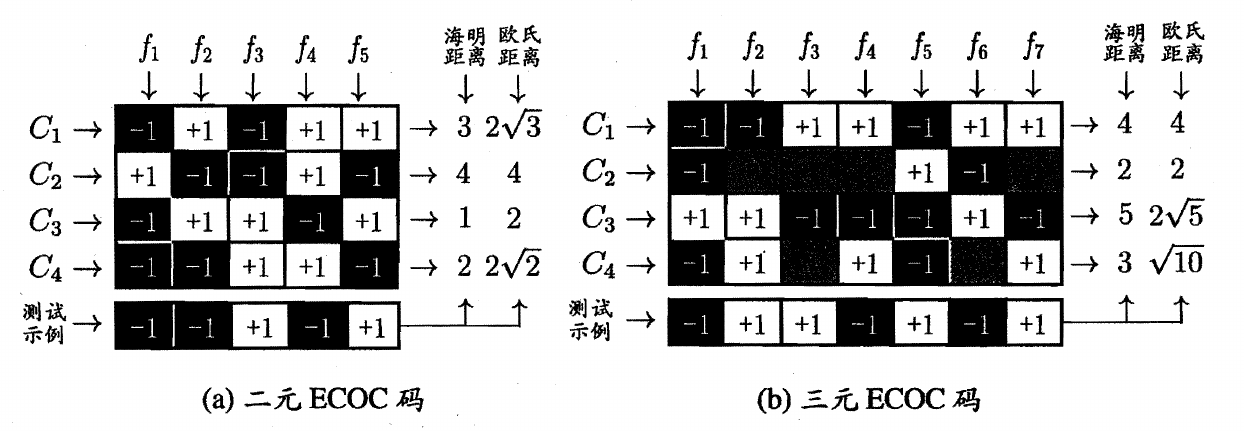
ECOC 常见的有二元码和三元码,类别和类别划分组成编码矩阵,其中 1 表示正类,-1 表示负类
a 图中分类器 f1 的预测结果为 (−1,+1,−1,−1),f2 的预测结果为 (+1,−1,+1,−1),f3 的预测结果为 (−1,−1,+1,+1),f4 的预测结果为 (+1,+1,−1,+1),f5 的预测结果为 (+1,−1,+1,−1),对于 C1 类别组成了一个编码 (−1,+1,−1,+1,+1),使用该编码与测试样本的编码进行比较
对于同一个学习任务,一般编码越长,纠错能力越强,但编码越长,所需的分类器越多,训练开销越大
类别不平衡问题
类别不平衡是指分类任务重不同类别的训练样本数目差别很大,同时在使用 OvR 和 MVM 拆分多分类问题时也可能导致类别不平衡
使用再缩放策略解决类别不平衡问题
通常认为正反例的可能性相同,当正例几率大于 0.5 时预测为正例
1−yy>1
当正反例的数目不同时,假设训练集是真实样本集的无偏采样,当正例几率大于数据集中正例的观测几率就可以判为正例
1−yy>m−m+
对预测值进行再缩放调整
1−y′y′=1−yy×m+m−
实际操作中观测几率通常不能代表真实几率,此时使用三种方法处理
- 多数样本欠采样:删除多数样本
- 少数样本过采样:通常使用插值增加样本
- 阈值移动:将再缩放方法加入决策过程中